データ収集
Twitter APIを使用してブランドに言及しているツイートを収集します。
ツイートデータの定期的な収集に関しては「GCPを活用したSNS解析サービスの構築」のページを参照してください。
ブランドイメージ抽出
例えば指定のキーワードを含む「新商品のチョコレートがすごくおいしい」というツイートを形態素解析した場合、以下のようになります。
>新 接頭詞,名詞接続,,,,,新,シン,シン
商品 名詞,一般,*,*,*,*,商品,ショウヒン,ショーヒン
の 助詞,連体化,*,*,*,*,の,ノ,ノ
チョコレート 名詞,一般,*,*,*,*,チョコレート,チョコレート,チョコレート
が 助詞,格助詞,一般,*,*,*,が,ガ,ガ
すごく 形容詞,自立,*,*,形容詞・アウオ段,連用テ接続,すごい,スゴク,スゴク
おいしい 形容詞,自立,*,*,形容詞・イ段,基本形,おいしい,オイシイ,オイシイ
収集したデータを自然言語処理を用いて形態素解析を行います。
例えば指定のキーワードを含むツイートの一部が以下のような場合
「新商品のチョコレートがすごくおいしい」
形態素解析を行うと以下のようになります。
大量のツイートに対して同様の処理を行うことでブランドに触れた人がどのようなイメージを持っているのかを抽出することができます。上記の例では「おいしい」がキーワードから連想されていることがわかります。単純に出現回数の多い順番に並べると助詞などのそれ自体に意味がない単語が上位に来ることがあるため、品詞を絞ったり予め作成した辞書と照らし合わせたりするなどしてイメージを抽出します。
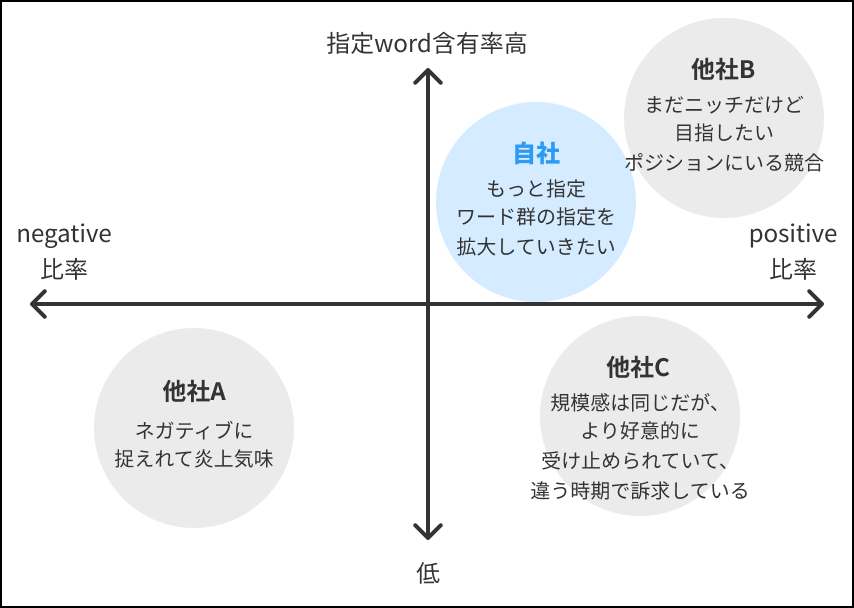
競合との比較
機械学習を用いると各ツイートの内容がポジティブかネガティブかの判定も可能です。また、競合ブランドをキーワードとしてデータを収集し、同様の処理を実行することでブランドのイメージを比較することが可能です。ツイートされた数、感情分析などの情報を用いて、競合ブランドとの関係を可視化してポジショニングマップを作成できます。例えば競合と比較してどれくらいSNSで話題に上がっているか、指定したキーワードがどれくらい含まれているのか、など様々な角度からデータの分析を行い、マーケティング施策に活かすことが可能です。
関連項目
 SNS分析による広告効果測定ビッグデータすなわちWEBの行動データに基づき広告KPIおよびコミュニケーションKPIを計測する手法の開発を進めています。分析技術
SNS分析による広告効果測定ビッグデータすなわちWEBの行動データに基づき広告KPIおよびコミュニケーションKPIを計測する手法の開発を進めています。分析技術 人流分析ビッグデータすなわちWEBの行動データに基づき広告KPIおよびコミュニケーションKPIを計測する手法の開発を進めています。開発技術
人流分析ビッグデータすなわちWEBの行動データに基づき広告KPIおよびコミュニケーションKPIを計測する手法の開発を進めています。開発技術 コンテキストターゲティングビッグデータすなわちWEBの行動データに基づき広告KPIおよびコミュニケーションKPIを計測する手法の開発を進めています。プラットフォーム
コンテキストターゲティングビッグデータすなわちWEBの行動データに基づき広告KPIおよびコミュニケーションKPIを計測する手法の開発を進めています。プラットフォーム 広告予算の最適配分ビッグデータすなわちWEBの行動データに基づき広告KPIおよびコミュニケーションKPIを計測する手法の開発を進めています。データサイエンス
広告予算の最適配分ビッグデータすなわちWEBの行動データに基づき広告KPIおよびコミュニケーションKPIを計測する手法の開発を進めています。データサイエンス 社内文章検索エンジンビッグデータすなわちWEBの行動データに基づき広告KPIおよびコミュニケーションKPIを計測する手法の開発を進めています。応用産業
社内文章検索エンジンビッグデータすなわちWEBの行動データに基づき広告KPIおよびコミュニケーションKPIを計測する手法の開発を進めています。応用産業 観光地レコメンドビッグデータすなわちWEBの行動データに基づき広告KPIおよびコミュニケーションKPIを計測する手法の開発を進めています。分析技術
観光地レコメンドビッグデータすなわちWEBの行動データに基づき広告KPIおよびコミュニケーションKPIを計測する手法の開発を進めています。分析技術 SNSからブランドイメージ抽出ビッグデータすなわちWEBの行動データに基づき広告KPIおよびコミュニケーションKPIを計測する手法の開発を進めています。プラットフォーム
SNSからブランドイメージ抽出ビッグデータすなわちWEBの行動データに基づき広告KPIおよびコミュニケーションKPIを計測する手法の開発を進めています。プラットフォーム 車の走行データ分析ビッグデータすなわちWEBの行動データに基づき広告KPIおよびコミュニケーションKPIを計測する手法の開発を進めています。データサイエンス
車の走行データ分析ビッグデータすなわちWEBの行動データに基づき広告KPIおよびコミュニケーションKPIを計測する手法の開発を進めています。データサイエンス 作業者の行動漏れ検知ビッグデータすなわちWEBの行動データに基づき広告KPIおよびコミュニケーションKPIを計測する手法の開発を進めています。データサイエンス
作業者の行動漏れ検知ビッグデータすなわちWEBの行動データに基づき広告KPIおよびコミュニケーションKPIを計測する手法の開発を進めています。データサイエンス 表情から感情推定ビッグデータすなわちWEBの行動データに基づき広告KPIおよびコミュニケーションKPIを計測する手法の開発を進めています。応用産業
表情から感情推定ビッグデータすなわちWEBの行動データに基づき広告KPIおよびコミュニケーションKPIを計測する手法の開発を進めています。応用産業 会議音声からキーワード抽出ビッグデータすなわちWEBの行動データに基づき広告KPIおよびコミュニケーションKPIを計測する手法の開発を進めています。開発技術
会議音声からキーワード抽出ビッグデータすなわちWEBの行動データに基づき広告KPIおよびコミュニケーションKPIを計測する手法の開発を進めています。開発技術 GCPを活用したSNS解析サービスの構築ビッグデータすなわちWEBの行動データに基づき広告KPIおよびコミュニケーションKPIを計測する手法の開発を進めています。データサイエンス
GCPを活用したSNS解析サービスの構築ビッグデータすなわちWEBの行動データに基づき広告KPIおよびコミュニケーションKPIを計測する手法の開発を進めています。データサイエンス