対象読者
- 機械学習がどのようなものかわかり、画像生成に興味がある方
- 画像生成がどのように行われているか知りたい方
- 画像生成モデルの雰囲気を掴みたい方
目標
- 画像生成分野の基本的な手法の雰囲気を掴むこと
画像生成タスク
その名の通り、「ありそうな」画像を生成するモデルを構築するタスク。
顔画像を例によると、「いそう」だけど「実際にはいない人の」顔画像を生成するモデルを構築する。
主要な手法
一般的によく使われる画像生成モデルは大きく以下の2つに大別できます。
- VAE系
- GAN系
この他にもFlowベースの手法などもありますが、今回は対象外とします。
次にそれぞれの手法を簡単に概観します。
VAE
VAEは2013年に提案された教師なし学習モデルで、構造を端的に述べるとエンコーダー・デコーダーモデルです。
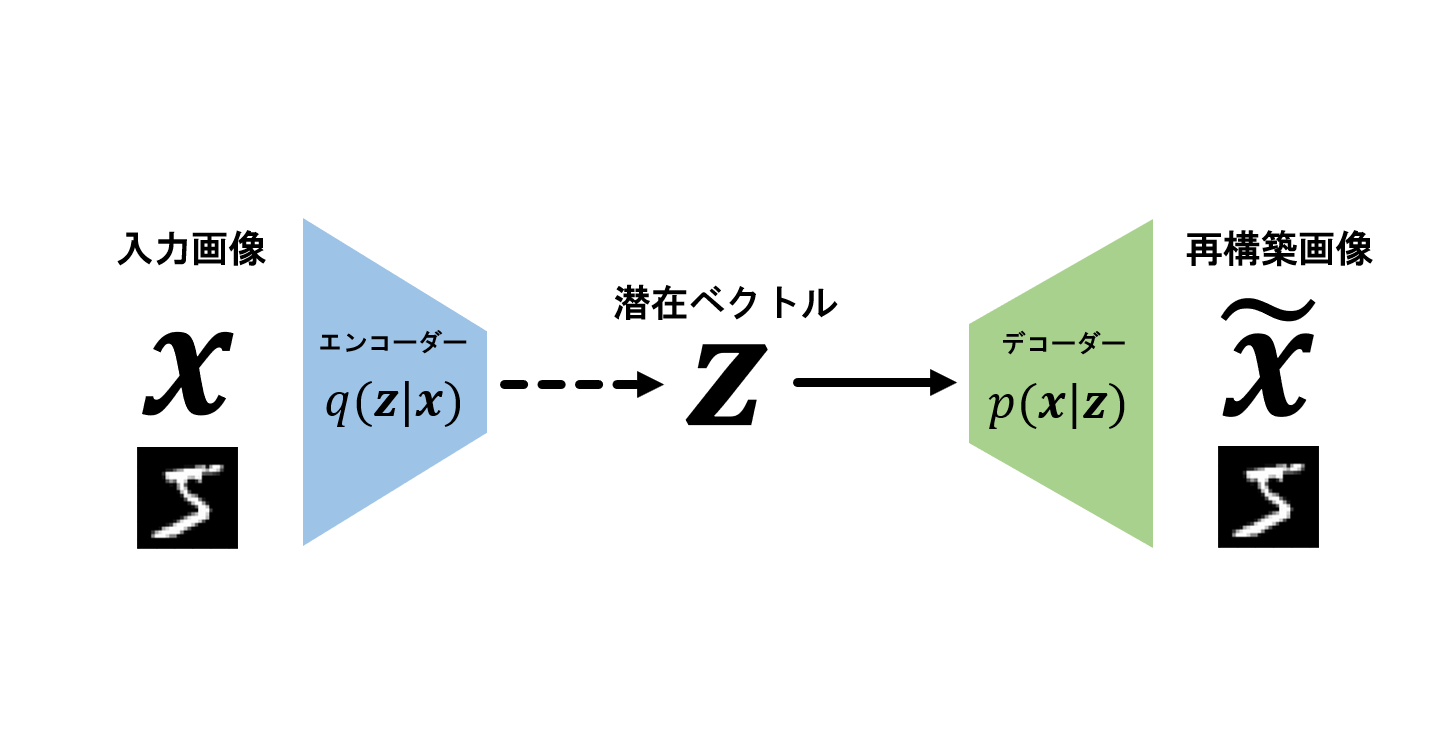
下図を用いてもう少し詳しく説明していきます。

ここでは、MNISTの手書き数字データセットを例にとり、流れを説明します。
- 画像~\mathbf{x}~をエンコーダー~q_{\phi}(\mathbf{z}|\mathbf{x})~に入力し、潜在変数~\mathbf{z}~を出力
- 潜在変数zをデコーダー~p_{\theta}(\mathbf{x}|\mathbf{z})~に入力し、元の画像~\mathbf{x}~にできるだけ近い画像~\mathbf{\hat{x}}~を出力
ここで、重要となるのが「潜在変数~\mathbf{z}~」の存在です。
潜在変数~\mathbf{z}~を10次元として考えてみます。
もし仮に画像~\mathbf{x}~ (28×28=784要素)を10次元の潜在変数~\mathbf{z}~に変換し、再構築した画像~\mathbf{\hat{x}}~が元の画像~\mathbf{x}~を完璧に再現できるならば、このとき得られた潜在変数~\mathbf{z}~はたった10個の数字で784個の特徴からなる画像を完全再現できることになります。
要するに、この手書き数字画像はたった10個の特徴の組み合わせで表現でき(エンコードでき)、尚且つ10個の特徴の組み合わせで再現できる(デコードできる)ことになります。
このとき、エンコーダーは画像情報を低次元(10次元)に圧縮するモデル、デコーダーは低次元(10次元)の情報から画像を生成するモデルとみなすことができます。
デコーダーは10次元の入力から画像を生成することができるので、適当な値を入力することで、新たな画像を生成することができます。
以上がVAEを用いた画像生成の概要です。次回のブログでもう少し理論的な部分の解説をしたいと思います。
GAN
GANは2014年に提案された教師なし学習モデルです。以降では、下図を用いて説明していきます。

ここでもMNISTの手書き数字データセットで例を示します。
このモデルは生成器(G)と識別器(D)の2つのネットワークからなります。
このモデルの目的は、生成器Gにより「本物と見分けのつかない画像」を生成することです。では、具体的にどのようにそのような生成器を学習するかを見ていきます。
- GANの学習の流れ
- 生成器Gに適当なノイズを入力し、偽物の画像を生成
- 本物の画像(訓練データ)と偽物の画像(生成器の出力)の2種類のデータを入力として識別器Dを学習
- 識別器Dをだますことができるように生成器Gを学習 → 2. に戻る
このように「いたちごっこ」で学習していくことで、うまく学習できれば最終的に、識別器Dによって本物と見分けがつかないような偽画像を出力する生成器Gを構築することができます。その生成器に適当なノイズを入力すれば新たな画像を生成することができます。
以上GANによる簡単な画像生成の流れです。
まとめ
VAEやGANといった画像生成モデルの概観について簡単に説明しました。画像生成の応用は面白いものが多いので、興味のある方は是非調べてみてください。
次回のブログではVAEの理論的な部分について解説していきたいと思います。