はじめに
前編 の続きです。Excelでできるデータドリブン・マーケティングという本の第3章をPythonで実装しています。
corrメソッドやcorrcoef関数を用いて相関係数行列を求める
corrcoef関数やnumpyのcorrメソッドを使うと簡単に相関係数行列を出力することができます。
3-4 どの変数が目的変数に影響がありそうか? 相関係数でチェック
相関係数行列を出力します。
import numpy as np
cor_matrix = df.corr()
#cor_matrix = np.corrcoef([df['amount'], df['TVCM'], df['paper'], df['OOH'], df['WEB']]) も可
cor_matrix| amount | TVCM | paper | OOH | WEB | |
|---|---|---|---|---|---|
| amount | 1.000000 | 0.505210 | 0.435052 | 0.098626 | 0.679399 |
| TVCM | 0.505210 | 1.000000 | 0.471050 | 0.317986 | 0.526497 |
| paper | 0.435052 | 0.471050 | 1.000000 | 0.447858 | 0.371966 |
| OOH | 0.098626 | 0.317986 | 0.447858 | 1.000000 | 0.226459 |
| WEB | 0.679399 | 0.526497 | 0.371966 | 0.226459 | 1.000000 |
3-5 相関係数を参考にする際の注意 「疑似相関」
疑似相関に気を付けましょうという話が書かれていました。問題の掲載がなかったので次に進みます。
3-6 「エクセル統計」で偏相関係数行列と「無向グラフ」を作成
偏相関係数行列を作成します. 以下の記事を参考にさせていただきました。
pythonで偏相関係数行列(pcor)を計算
Pythonで多変量解析、3変数以上の偏相関係数を算出してみた
生データのpandas dfから偏相関行列を求めるプログラム
多変量解析の多重共線性を調べるために相関行列から偏相関行列をExcelで求める方法
二つのステップに分けて考えました。
一つ目は逆行列を求めることです。scipyライブラリのlinalgを用います。linalg.inv メソッドを用いて逆行列を求めます。
import scipy.linalg as linalg # 線形代数の計算に用いるライブラリ
cor_matrix_inv = linalg.inv(cor_matrix)
cor_matrix_invarray([[ 2.1695598 , -0.35678987, -0.5129779 , 0.39766342, -1.18539179],
[-0.35678987, 1.65531469, -0.35561592, -0.23125784, -0.44446851],
[-0.5129779 , -0.35561592, 1.62705147, -0.57897692, 0.06165441],
[ 0.39766342, -0.23125784, -0.57897692, 1.34756443, -0.23822438],
[-1.18539179, -0.44446851, 0.06165441, -0.23822438, 2.07038006]])二つ目は、各要素に対してその対角成分の積を計算し平方根をとったもので割り、符号を逆にするという操作です。
l = cor_matrix_inv.shape[0] # 逆行列の行数
array_diag = np.diag(cor_matrix_inv) # 対角成分
tmp_list = []
for i in range(l):
tmp_list2 = []
for j in range(l):
if i == j:
tmp_list2.append(1)
else:
tmp = -(cor_matrix_inv[i, j] / np.sqrt(cor_matrix_inv[i, i] * cor_matrix_inv[j, j]))
tmp_list2.append(tmp)
tmp_list.append(tmp_list2)
names = ['amount', 'TVCM', 'paper', 'OOH', 'WEB']
df_pcor = pd.DataFrame(tmp_list, index=names, columns=names)
df_pcor| amount | TVCM | paper | OOH | WEB | |
|---|---|---|---|---|---|
| amount | 1.000000 | 0.188272 | 0.273031 | -0.232571 | 0.559308 |
| TVCM | 0.188272 | 1.000000 | 0.216691 | 0.154839 | 0.240091 |
| paper | 0.273031 | 0.216691 | 1.000000 | 0.391008 | -0.033592 |
| OOH | -0.232571 | 0.154839 | 0.391008 | 1.000000 | 0.142622 |
| WEB | 0.559308 | 0.240091 | -0.033592 | 0.142622 | 1.000000 |
偏相関係数行列を求めることができました。
次に相関係数を可視化するための無向グラフを出力します。以下の記事を参考にさせていただきました。
import networkx as nx
import matplotlib.pyplot as plt
G = nx.Graph() # 空の無向グラフを作成
l = len(df_pcor) # 相関係数行列の行数
edges = [[names[i], names[j], df_pcor.iloc[i, j]] for i in range(l) for j in range(i,l)]
G.add_weighted_edges_from(edges)
# ネットワークの描画
plt.figure(figsize=[15, 10])
nx.draw_networkx(G)
plt.show()
本のように正五角形にするために、頂点の位置を調整します。以下の記事を参考にさせていただきました。
import numpy as np
pos = {names[i]: (np.cos(2*i*np.pi/l + np.pi/2), np.sin(2*i*np.pi/l + np.pi/2)) for i in range(l)}
# ネットワークの描画
plt.figure(figsize=[15, 10])
nx.draw_networkx(G, pos)
plt.show()
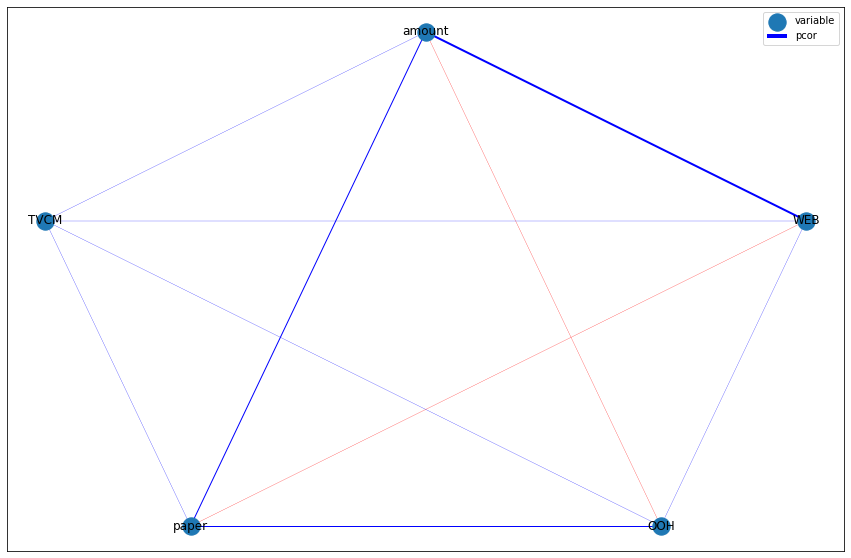
相関係数の値に応じて、辺の色や太さを変えていきます。色は負の値なら赤に、正の値ならば青になるようにします。辺の太さは絶対値が大きくなるにつれて太くなるようにします。
# 辺の色を決める関数
def pcor_color(n):
if n < 0:
c = 'red'
else:
c = 'blue'
return c
# 辺の幅を決める関数
def pcor_width(n):
if -0.25 <= n < 0.25:
w = 0.25
elif -0.50 <= n < 0.50:
w = 1.0
elif -0.75 <= n < 0.75:
w = 2.0
else:
w = 4.0
return w
color_list = [pcor_color(df_pcor.iloc[i, j]) for i in range(l) for j in range(i, l)] # 辺の色
width_list = [pcor_width(df_pcor.iloc[i, j]) for i in range(l) for j in range(i, l)] # 辺の幅
# ネットワークの描画
plt.figure(figsize=[15, 10])
nx.draw_networkx(G, pos, width=width_list, edge_color=color_list)
plt.legend(['variable', 'pcor'], loc='best') # 凡例
plt.show()
3-7 「エクセル統計」の「期別平均法」で季節性を把握
データの周期性を確認します。新しいデータを読み込みます。本で指示されたファイルをcsv形式にしてダウンロードし、保存します。ファイル名は5years_amount.csvとしました。また、データフレームの名称は先ほどと同じにならないよう df_5years としました。
import pandas as pd
df_5years = pd.read_csv('5years_amount.csv')Google Colaboratory をご利用の方は以下を参考にしてください。
# Google Colaboratory用
df_5years = pd.read_csv('/content/drive/My Drive/DDM_chap3/5years_amount.csv')次にデータフレームを周期ごとに分割し、横持ちにします。pandasのshiftメソッドを用いてデータを12個ずらし、ずらしたデータを結合するという操作を繰り返します。
for i in range(4):
if i == 0:
df_5years_new = pd.concat([df_5years, df_5years.shift(-12*(i+1))], axis=1)
else:
df_5years_new = pd.concat([df_5years_new, df_5years.shift(-12*(i+1))], axis=1)
df_5years_new = df_5years_new[:12]
df_5years_new| month | amount | month | amount | month | amount | month | amount | month | amount | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Jan-13 | 23855873 | Jan-14 | 24779476.0 | Jan-15 | 22736161.0 | Jan-16 | 23625790.0 | Jan-17 | 23769073.0 |
| 1 | Feb-13 | 21169392 | Feb-14 | 21545753.0 | Feb-15 | 23244992.0 | Feb-16 | 22454998.0 | Feb-17 | 21885013.0 |
| 2 | Mar-13 | 27123037 | Mar-14 | 27534055.0 | Mar-15 | 28575107.0 | Mar-16 | 26235506.0 | Mar-17 | 29844870.0 |
| 3 | Apr-13 | 22870090 | Apr-14 | 22279253.0 | Apr-15 | 22377198.0 | Apr-16 | 22450989.0 | Apr-17 | 23393576.0 |
| 4 | May-13 | 26411442 | May-14 | 27297736.0 | May-15 | 27322086.0 | May-16 | 27776729.0 | May-17 | 27647825.0 |
| 5 | Jun-13 | 26245163 | Jun-14 | 25288740.0 | Jun-15 | 27018107.0 | Jun-16 | 25127312.0 | Jun-17 | 27958753.0 |
| 6 | Jul-13 | 28561595 | Jul-14 | 28460146.0 | Jul-15 | 29416862.0 | Jul-16 | 26573014.0 | Jul-17 | 31478713.0 |
| 7 | Aug-13 | 30984498 | Aug-14 | 31375696.0 | Aug-15 | 31391512.0 | Aug-16 | 31923075.0 | Aug-17 | 31242331.0 |
| 8 | Sep-13 | 24278571 | Sep-14 | 23811584.0 | Sep-15 | 24242482.0 | Sep-16 | 24442619.0 | Sep-17 | 26280076.0 |
| 9 | Oct-13 | 23901606 | Oct-14 | 25148353.0 | Oct-15 | 27520610.0 | Oct-16 | 22003869.0 | Oct-17 | 26193034.0 |
| 10 | Nov-13 | 24014235 | Nov-14 | 24281710.0 | Nov-15 | 25350761.0 | Nov-16 | 23481832.0 | NaN | NaN |
| 11 | Dec-13 | 26289807 | Dec-14 | 26470527.0 | Dec-15 | 26417480.0 | Dec-16 | 26422865.0 | NaN | NaN |
本の表記にあわせるためにmonth列を削除し、index(行名)を月にしていきます。
また、amountという列名の列が5つあり不便です。どの年のデータかすぐにわかるように列名を変更します。
df_5years_new = df_5years_new.drop(['month'], axis=1)df_5years_new.columns = [df_5years_new.columns[i] + str(i+2013) for i in range(5)]df_5years_new.index = df_5years[0:12].month.apply(lambda x: x[0:3])
df_5years_new| amount2013 | amount2014 | amount2015 | amount2016 | amount2017 | |
|---|---|---|---|---|---|
| month | |||||
| Jan | 23855873 | 24779476.0 | 22736161.0 | 23625790.0 | 23769073.0 |
| Feb | 21169392 | 21545753.0 | 23244992.0 | 22454998.0 | 21885013.0 |
| Mar | 27123037 | 27534055.0 | 28575107.0 | 26235506.0 | 29844870.0 |
| Apr | 22870090 | 22279253.0 | 22377198.0 | 22450989.0 | 23393576.0 |
| May | 26411442 | 27297736.0 | 27322086.0 | 27776729.0 | 27647825.0 |
| Jun | 26245163 | 25288740.0 | 27018107.0 | 25127312.0 | 27958753.0 |
| Jul | 28561595 | 28460146.0 | 29416862.0 | 26573014.0 | 31478713.0 |
| Aug | 30984498 | 31375696.0 | 31391512.0 | 31923075.0 | 31242331.0 |
| Sep | 24278571 | 23811584.0 | 24242482.0 | 24442619.0 | 26280076.0 |
| Oct | 23901606 | 25148353.0 | 27520610.0 | 22003869.0 | 26193034.0 |
| Nov | 24014235 | 24281710.0 | 25350761.0 | 23481832.0 | NaN |
| Dec | 26289807 | 26470527.0 | 26417480.0 | 26422865.0 | NaN |
次に月ごとの平均値を求めます。引数skipnaをTrueとしていますが、デフォルトでもTrueです。
df_5years_new['average'] = df_5years_new.mean(axis=1, skipna=True)
df_5years_new| amount2013 | amount2014 | amount2015 | amount2016 | amount2017 | average | |
|---|---|---|---|---|---|---|
| month | ||||||
| Jan | 23855873 | 24779476.0 | 22736161.0 | 23625790.0 | 23769073.0 | 23753274.60 |
| Feb | 21169392 | 21545753.0 | 23244992.0 | 22454998.0 | 21885013.0 | 22060029.60 |
| Mar | 27123037 | 27534055.0 | 28575107.0 | 26235506.0 | 29844870.0 | 27862515.00 |
| Apr | 22870090 | 22279253.0 | 22377198.0 | 22450989.0 | 23393576.0 | 22674221.20 |
| May | 26411442 | 27297736.0 | 27322086.0 | 27776729.0 | 27647825.0 | 27291163.60 |
| Jun | 26245163 | 25288740.0 | 27018107.0 | 25127312.0 | 27958753.0 | 26327615.00 |
| Jul | 28561595 | 28460146.0 | 29416862.0 | 26573014.0 | 31478713.0 | 28898066.00 |
| Aug | 30984498 | 31375696.0 | 31391512.0 | 31923075.0 | 31242331.0 | 31383422.40 |
| Sep | 24278571 | 23811584.0 | 24242482.0 | 24442619.0 | 26280076.0 | 24611066.40 |
| Oct | 23901606 | 25148353.0 | 27520610.0 | 22003869.0 | 26193034.0 | 24953494.40 |
| Nov | 24014235 | 24281710.0 | 25350761.0 | 23481832.0 | NaN | 24282134.50 |
| Dec | 26289807 | 26470527.0 | 26417480.0 | 26422865.0 | NaN | 26400169.75 |
tmp_ave = df_5years_new['average'].mean()
df_5years_new['seasonal_index'] = df_5years_new.average.apply(lambda x: x / tmp_ave)
df_5years_new| amount2013 | amount2014 | amount2015 | amount2016 | amount2017 | average | seasonal_index | |
|---|---|---|---|---|---|---|---|
| month | |||||||
| Jan | 23855873 | 24779476.0 | 22736161.0 | 23625790.0 | 23769073.0 | 23753274.60 | 0.918009 |
| Feb | 21169392 | 21545753.0 | 23244992.0 | 22454998.0 | 21885013.0 | 22060029.60 | 0.852569 |
| Mar | 27123037 | 27534055.0 | 28575107.0 | 26235506.0 | 29844870.0 | 27862515.00 | 1.076822 |
| Apr | 22870090 | 22279253.0 | 22377198.0 | 22450989.0 | 23393576.0 | 22674221.20 | 0.876306 |
| May | 26411442 | 27297736.0 | 27322086.0 | 27776729.0 | 27647825.0 | 27291163.60 | 1.054741 |
| Jun | 26245163 | 25288740.0 | 27018107.0 | 25127312.0 | 27958753.0 | 26327615.00 | 1.017502 |
| Jul | 28561595 | 28460146.0 | 29416862.0 | 26573014.0 | 31478713.0 | 28898066.00 | 1.116844 |
| Aug | 30984498 | 31375696.0 | 31391512.0 | 31923075.0 | 31242331.0 | 31383422.40 | 1.212897 |
| Sep | 24278571 | 23811584.0 | 24242482.0 | 24442619.0 | 26280076.0 | 24611066.40 | 0.951161 |
| Oct | 23901606 | 25148353.0 | 27520610.0 | 22003869.0 | 26193034.0 | 24953494.40 | 0.964395 |
| Nov | 24014235 | 24281710.0 | 25350761.0 | 23481832.0 | NaN | 24282134.50 | 0.938449 |
| Dec | 26289807 | 26470527.0 | 26417480.0 | 26422865.0 | NaN | 26400169.75 | 1.020306 |
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(15,9))
plt.plot(df_5years_new[df_5years_new.columns.drop('seasonal_index')])
ax.set_ylim([0, 35000000]) # 縦軸の範囲を調整
plt.xlabel('month')
plt.title('amount & average')
plt.legend(df_5years_new, loc='best')
plt.show()
fig, ax = plt.subplots(figsize=(15,9))
plt.plot(df_5years_new.seasonal_index)
ax.set_ylim([0, 1.4]) # 縦軸の範囲を調整
plt.xlabel('month')
plt.title('seasonal index')
plt.legend(['seasonal index'], loc='best')
plt.show()
まとめ
データ分析の際に必要なデータのまとめや可視化がバランスよく豊富に盛り込まれており、練習にぴったりでした。尚、この記事ではpythonの練習問題としてExcelでできるデータドリブン・マーケティングの一部を利用させていただきましたが、マーケティングの勉強が本来の目的であり、その観点からしても大変有名で面白い本なので是非通して読んでみてください。