
もっと麻雀AIを作ってみよう
あがり形推測モデル
ツモ!リーヅモチートイウラウラしてますか?
配牌を開け、目を走らせ、理牌する(あるいは勝手にされる)。その時に自分の手をどう進めるか構想を立てることだと初心者はよく言われます。
字牌を抱えて守備気味進行?いっそ配牌降り?そういう難しいのはよくわかりません。
手元に集まってきた牌で美しいあがりの形を描くことが大事だと、大人気プロ雀士の大地渚さんも言っています。麻雀AIにも渚さんのような雀士に育ってほしいので、あがりの形を勉強させましょう。
前回の記事では、牌姿を画像のように捉え、画像系モデルでよく利用されるCNNを用いて手役を学習させました。
手役を推測する麻雀AI作ってみた
今回もあがりの形を一つの「絵」のように捉えると、画像や異常検知の分野で用いられる生成モデルが使えそうですね。
生成モデルの概要については以下の記事を参照してください。
画像生成モデル(VAE・GAN)の概要
ちなみに、今回のモデルとは逆に、あがりの形から配牌を生成している方もいらっしゃいます。こちらの記事ではVAE系の生成モデルを使っているようです。
Aligned Variational Autoencoder で麻雀の配牌を生成する
pix2pix
配牌という条件が与えられるので、今回は条件付き生成モデルを用いることができそうです。さらに配牌と画像が同じサイズのペアと捉えることができるので、GANの一種のpix2pixを用いることができそうですね。線画(条件)を与えて色が塗られた画像(生成結果)を得るなどが代表的な利用例です。
(引用先)
今回は配牌(条件)を与えてあがりの形(生成結果)を得られるように学習していきます。
コード全体は最後にまとめました。
- 環境:Google colaboratory
- 機械学習フレームワーク:Pytorch
インプットデータ
天鳳の対局データからあがりの形と、その時の配牌を抽出します。あがれなかった配牌のことは忘れましょう。
前回と同様、こちらの記事からデータを利用させていただきました。
【麻雀AI】天鳳鳳凰卓の9年分のプレイをCNNを用いたNNモデルに学習させてみた
前回のモデルでも行っていた前処理ですが、手牌やあがりの形が同じなら、内部でどの牌を使っていたとしても入力は同じにしようと思います。
天鳳のデータでは、各牌に0~135までの固有IDが振られていますが(haipai_id, agari_id)、これを一度牌種のIDに直します(haipai_hai_id, agari_hai_id)。
| haipai_id | haipai_str | haipai_hai_id | agari_id | agari_str | agari_hai_id |
|---|---|---|---|---|---|
| [29, 38, 42, 45, 65, 69, 75, 85, 96, 115, 118, 125, 126] | [八, ①, ②, ③, ⑧, ⑨, 1, 4, 7, 南, 西, 白, 白] | [7, 9, 10, 11, 16, 17, 18, 21, 24, 28, 29, 31, 31] | [38, 42, 45, 69, 70, 85, 88, 94, 96, 101, 106, 124, 125, 126] | [①, ②, ③, ⑨, ⑨, 4, 5, 6, 7, 8, 9, 白, 白, 白] | [9, 10, 11, 17, 17, 21, 22, 23, 24, 25, 26, 31, 31, 31] |
| [6, 20, 22, 27, 50, 55, 65, 99, 101, 103, 108, 123, 124] | [二, 六, 六, 七, ④, ⑤, ⑧, 7, 8, 8, 東, 北, 白] | [1, 5, 5, 6, 12, 13, 16, 24, 25, 25, 27, 30, 31] | [5, 6, 20, 22, 23, 50, 55, 59, 91, 94, 99, 101, 102, 103] | [二, 二, 六, 六, 六, ④, ⑤, ⑥, 5, 6, 7, 8, 8, 8] | [1, 1, 5, 5, 5, 12, 13, 14, 22, 23, 24, 25, 25, 25] |
| [26, 43, 52, 61, 70, 74, 76, 80, 93, 98, 101, 112, 130] | [七, ②, ⑤, ⑦, ⑨, 1, 2, 3, 6, 7, 8, 南, 發] | [6, 10, 13, 15, 17, 18, 19, 20, 23, 24, 25, 28, 32] | [1, 7, 11, 52, 56, 61, 74, 76, 80, 93, 94, 98, 101, 104] | [一, 二, 三, ⑤, ⑥, ⑦, 1, 2, 3, 6, 6, 7, 8, 9] | [0, 1, 2, 13, 14, 15, 18, 19, 20, 23, 23, 24, 25, 26] |
| [10, 20, 22, 27, 33, 46, 59, 64, 71, 78, 124, 130, 134] | [三, 六, 六, 七, 九, ③, ⑥, ⑧, ⑨, 2, 白, 發, 中] | [2, 5, 5, 6, 8, 11, 14, 16, 17, 19, 31, 32, 33] | [20, 22, 26, 27, 52, 54, 58, 59, 117, 118, 124, 125, 130, 131] | [六, 六, 七, 七, ⑤, ⑤, ⑥, ⑥, 西, 西, 白, 白, 發, 發] | [5, 5, 6, 6, 13, 13, 14, 14, 29, 29, 31, 31, 32, 32] |
| [3, 25, 42, 43, 44, 47, 54, 70, 90, 100, 104, 126, 133] | [一, 七, ②, ②, ③, ③, ⑤, ⑨, 5, 8, 9, 白, 中] | [0, 6, 10, 10, 11, 11, 13, 17, 22, 25, 26, 31, 33] | [9, 10, 11, 38, 39, 42, 43, 44, 47, 84, 85, 90, 94, 96] | [三, 三, 三, ①, ①, ②, ②, ③, ③, 4, 4, 5, 6, 7] | [2, 2, 2, 9, 9, 10, 10, 11, 11, 21, 21, 22, 23, 24] |
データセットにする際に、手牌に一枚目ならその牌種に割り当てられている一番若い番号になるように修正します。
class TehaiDataset(torch.utils.data.Dataset):
def __init__(self, input_df):
self.haipai_list = input_df["haipai_hai_id"].tolist()
self.agari_list = input_df["agari_hai_id"].tolist()
def __len__(self):
return len(self.haipai_list)
def __getitem__(self, index):
haipai, agari = self.pull_item(index)
return haipai, agari
def tehai_2d(self, tehai):
c = collections.Counter(tehai)
tehai_ar = np.zeros(4*9*4)
for i in c.items():
hai_id = i[0] # 牌の種類 0index
hai_times = i[1] # 枚数
hai_id_list = [hai_id*4+i for i in range(hai_times)]
for j in hai_id_list:
tehai_ar[j] = 1
tehai_m = tehai_ar[0:9*1*4].copy().reshape([-1, 4]) # 4, 9
tehai_p = tehai_ar[9*1*4:9*2*4].copy().reshape([-1, 4])
tehai_s = tehai_ar[9*2*4:9*3*4].copy().reshape([-1, 4])
tehai_z = tehai_ar[9*3*4:].copy().reshape([-1, 4])
tehai_ar = np.concatenate([tehai_m, tehai_p, tehai_s, tehai_z], 1)# 16. 9
tehai_ar = np.concatenate([tehai_ar, np.zeros((16-9)*16).reshape([-1, 16])], 0)# 16, 16
return tehai_ar # チャンネル数、枚数、牌
def pull_item(self, index):
haipai = self.haipai_list[index]
agari = self.agari_list[index]
haipai_all = torch.tensor(np.array([self.tehai_2d(haipai)]), dtype=torch.float32)
agari_all = torch.tensor(np.array([self.tehai_2d(agari)]), dtype=torch.float32)
return haipai_all, agari_all
さらにこれを多次元情報へ変換します。前回は1×16×9の三次元テンソルにしましたが、今回は何かと便利なので1×16×16の平べったい立方体のテンソルにリサイズすることにしました。

これでインプットの準備ができました。サンプルサイズは約270000でした。
モデルの概形
実装は下記コードをほとんど使わせていただきました。
参考:pix2pixを1から実装して白黒画像をカラー化してみた(PyTorch)
モデルはこんな感じ。
class Generator(nn.Module):
def __init__(self):
super().__init__()
self.enc1 = self.conv_bn_relu(in_ch=1, out_ch=16, kernel_size=5)
self.enc2 = self.conv_bn_relu(16, 32, kernel_size=3, pool_kernel=4)
self.enc3 = self.conv_bn_relu(32, 64, kernel_size=3, pool_kernel=2)
self.dec1 = self.conv_bn_relu(64, 32, kernel_size=3, pool_kernel=-2)
self.dec2 = self.conv_bn_relu(32 + 32, 16, kernel_size=3, pool_kernel=-4)
self.dec3 = nn.Sequential(
nn.Conv2d(16 + 16, 1, kernel_size=5, padding=2),
nn.Tanh()
)
def conv_bn_relu(self, in_ch, out_ch, kernel_size=3, pool_kernel=None):
layers = []
if pool_kernel is not None:
if pool_kernel > 0:
layers.append(nn.AvgPool2d(pool_kernel))
elif pool_kernel < 0:
layers.append(nn.UpsamplingNearest2d(scale_factor=-pool_kernel))
layers.append(nn.Conv2d(in_ch, out_ch, kernel_size, padding=(kernel_size - 1) // 2))
layers.append(nn.BatchNorm2d(out_ch))
layers.append(nn.ReLU(inplace=True))
return nn.Sequential(*layers)
def forward(self, x):
x1 = self.enc1(x)
x2 = self.enc2(x1)
x3 = self.enc3(x2)
out = self.dec1(x3)
out = self.dec2(torch.cat([out, x2], dim=1))
out = self.dec3(torch.cat([out, x1], dim=1))
return out
# 生成器オブジェクトを作成する
model_G = Generator().to(device)
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = self.conv_bn_relu(1, 16, kernel_size=5, reps=1)
self.conv2 = self.conv_bn_relu(16, 32, pool_kernel=4)
self.conv3 = self.conv_bn_relu(32, 64, pool_kernel=2)
self.out_patch = nn.Conv2d(64, 1, kernel_size=1)
def conv_bn_relu(self, in_ch, out_ch, kernel_size=3, pool_kernel=None, reps=2):
layers = []
for i in range(reps):
if i == 0 and pool_kernel is not None:
layers.append(nn.AvgPool2d(pool_kernel))
layers.append(nn.Conv2d(in_ch if i == 0 else out_ch,
out_ch, kernel_size, padding=(kernel_size - 1) // 2))
layers.append(nn.BatchNorm2d(out_ch))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
return self.out_patch(out)
# 生成器オブジェクトを作成する
model_D = Discriminator().to(device)
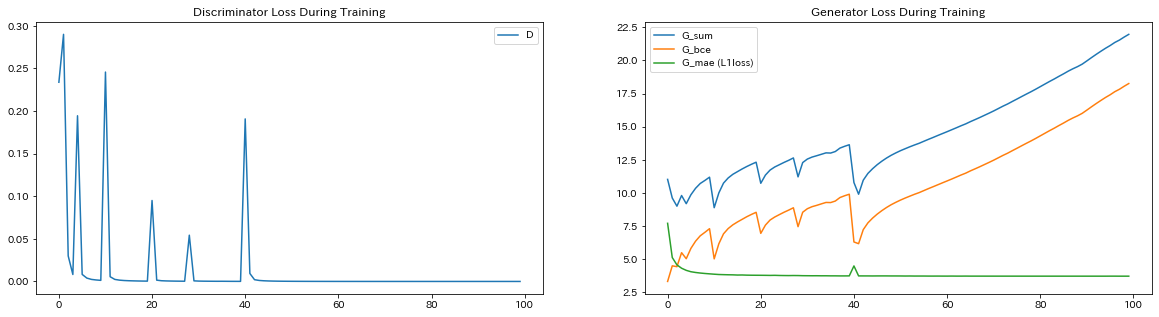
100エポックほどぶん回して様子を見てみると、順調にロスが動いているようです。Generator側の損失が増加し続けているのはなんだか変な感じがしますが、よくあることのようです。内部ではちゃんと小さくなろうとしています。
学習が終わったら、確率として出力されている結果に閾値を設けて0と1のデータに変換します。今回はかなり明瞭に1付近と0付近の二峰になっていたので、閾値は0.5としました。
学習済のモデルを使ってテストデータの配牌からあがり形を予測してみます。
| haipai_str | agari_str | fake_agari_str |
|---|---|---|
| [一, 七, 八, ②, ④, ⑥, ⑧, 4, 6, 7, 8, 8, 東] | [六, 七, 八, ⑥, ⑦, ⑧, 2, 3, 4, 6, 7, 8, 8, 8] | [六, 七, 八, ⑥, ⑦, ⑧, 2, 3, 4, 6, 7, 8, 8] |
| [三, 五, 六, ⑤, ⑥, ⑧, 4, 7, 8, 東, 北, 白, 白] | [五, 六, 七, ③, ④, ⑤, 4, 5, 6, 7, 7, 白, 白, 白] | [五, 六, 七, ③, ④, ⑤, 4, 5, 6, 7, 白, 白] |
| [二, 五, 六, 六, 七, 八, ⑧, 1, 3, 5, 9, 9, 東] | [四, 五, 六, 七, 八, 九, ⑧, ⑧, 3, 4, 5, 9, 9, 9] | [四, 五, 六, 七, 八, 九, ⑧, 3, 4, 5, 9, 9] |
| [二, 五, 五, ⑥, ⑧, ⑧, 4, 5, 6, 8, 西, 白, 中] | [四, 五, 五, 六, 六, 七, ⑧, ⑧, 3, 4, 5, 6, 7, 8] | [四, 五, 六, 七, ⑧, 3, 4, 5, 6, 7, 8] |
| [四, 九, ⑥, ⑥, 2, 4, 4, 6, 8, 8, 9, 中, 中] | [1, 2, 2, 3, 3, 4, 4, 5, 6, 8, 8, 中, 中, 中] | [1, 2, 3, 4, 5, 6, 8, 中, 中] |
おぉ? 悪くはなさそうです。
一般にpix2pixの評価はセマンティックセグメンテーションなどを利用して行うそうですが、今回は13種類×4枚の牌について「ある・なし」のラベルを当てるモデルとも捉えられるので、多ラベル問題と見て評価してみます。
参考:多ラベル分類の評価指標について
# macro-F1
average = "macro"
print("Precisionの平均:", precision_score(y_true=y_true, y_pred=y_pred, average=average))
print("Recallの平均:". recall_score(y_true=y_true, y_pred=y_pred, average=average))
print("macro-F1". f1_score(y_true=y_true, y_pred=y_pred, average=average))
# Precisionの平均: 1.0
# Recallの平均: 0.9993529126046559
# macro-F1 0.9996763083774404
# micro-F1
average = "micro"
print("Precisionの平均:", precision_score(y_true=y_true, y_pred=y_pred, average=average))
print("Recallの平均:", recall_score(y_true=y_true, y_pred=y_pred, average=average))
print("macro-F1", f1_score(y_true=y_true, y_pred=y_pred, average=average))
# Precisionの平均: 1.0
# Recallの平均: 0.9993839488041041
# macro-F1 0.9996918794930486
評価指標の上では頑張っているよう見えます。
最後に可視化して見比べてみましょう。

こうして見ると、順子を上手く当てていることが高評価につながっていそうです。
多くの局で、あがっている配牌は順子の元があるいい配牌と考えられます。順子は画像で例えると「点と点を縦の線でつなぐ」行為に当たるので、いい配牌からの予測はそこまで難しくないのかもしれません。
一方で、暗刻や雀頭(横の線)はあまり予測できていなさそうです。雀頭をいつどこで作るかは平和系の手の永遠の課題ですからね。
雀頭を予測できなかったために、結構なケースで牌の数が足りないこともわかりました。再現率が適合率に比べて低い値を出していることからもそれがわかります。正解データのあがり牌の数はほとんどのケースで14枚になるはずなので、生成器の学習する時になにかの制約をつけたら上手くいくかもしれません。
あがりの形の前にルールを教えたほうがよさそうですね。


